A transformer that allows one to convert CiceroMark into OOXML and vice-versa.
Author: Kushal Kumar
Accord Project
Accord Project is an organization that is developing an ecosystem and tools specifically for smart legal contracts.
About the Project
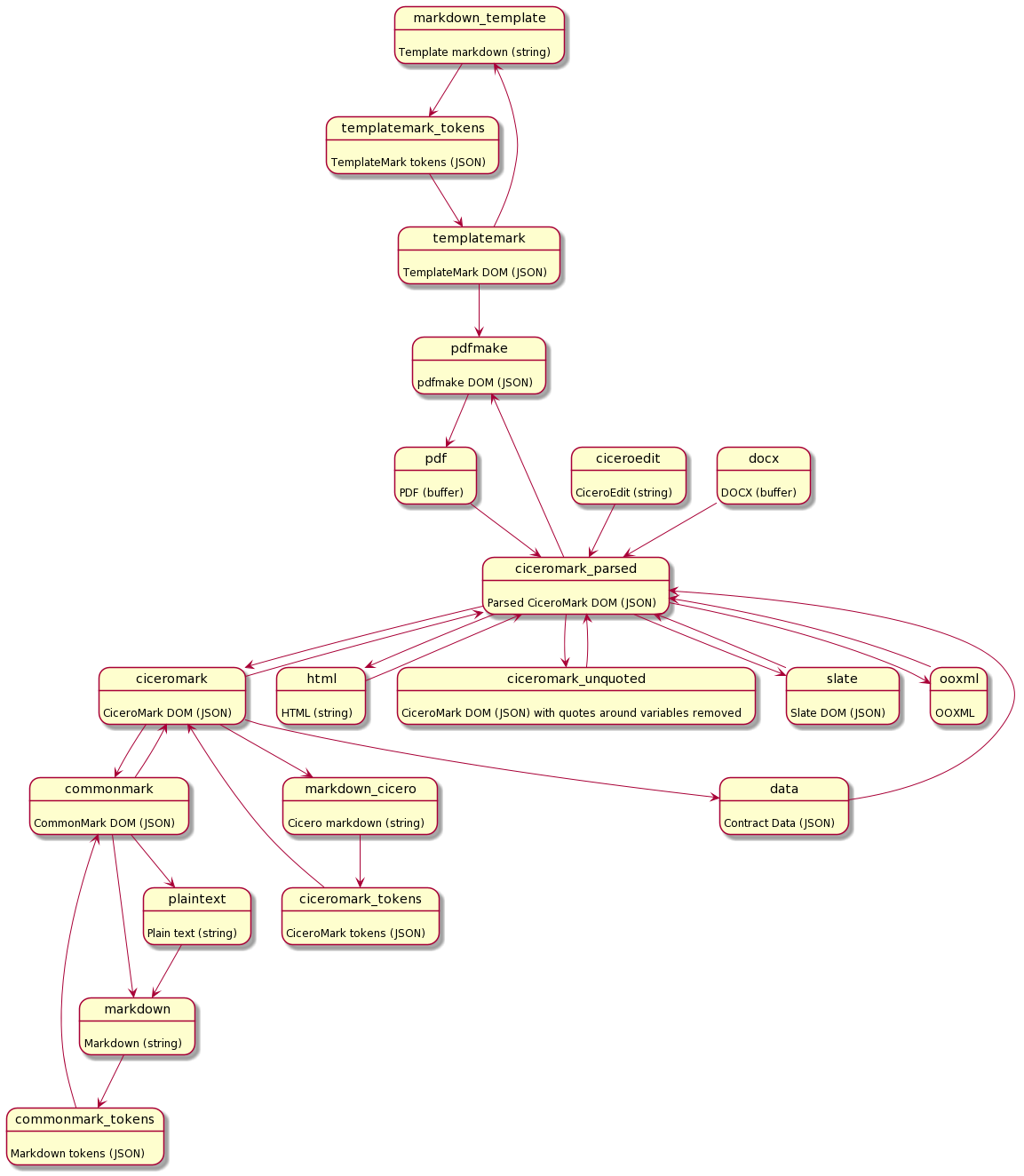
Accord Project creates templates for contracts and clauses using the cicero, ergo, and concerto. These templates, that are stored in .cta files can then be converted into different formats like md, pdf, json using the transformer library.
My task was to improve the transformer by allowing the CiceroMark<-> OOXML interconversion by including the logic for missing entities in the transformer and improve the existing transformations ensuring proper roundtrip between the two.
Use Case
By integrating the above transformation process, one can convert the templates into an XML file that can be opened with MS Word, making it easier for non-technical people to work with the contracts and clauses. An add-in is already created(not fully capable) which can make the interaction easier with these Word documents even before.
The blog post for the add-in can be read here.
OOXML
Office Open Extensible Markup Language abbreviated as OOXML is a zip-based XML file format which was developed by Microsoft. It can be used to represent documents, presentations, spreadsheets, etc. OOXML acts as the backbone of these documents as it is completely responsible for rendering the content which is visible on a word document or a presentation. The docx format is a representation of an OOXML which is supposed to be a “word processing document“. A basic structure of OOXML in word document:
<w:document> is the area that includes the text and styling tags. This was the area which on which I worked.
Pre-Coding
Apart from getting familiar with the project, I explored OOXML, CiceroMark, and the existing transformer. Some discussions involved the approach to integrate the transformer. Things like which nodes to transform have a higher priority and which can be made a lower priority were also decided. The transformer lied in the algoo-ooxml which was not updated frequently and was out of sync with the main branch. So, rebasing was done to sync them at the start. Besides this, a basic setup was done for the project. The corresponding details can be found in this blog.
Journey
After the community bonding period, it was time to get the hands dirty. The complete work was done on algoo-ooxml branch. Below is a sample CiceroMark and a tree structure for the same.
CiceroMark Structure
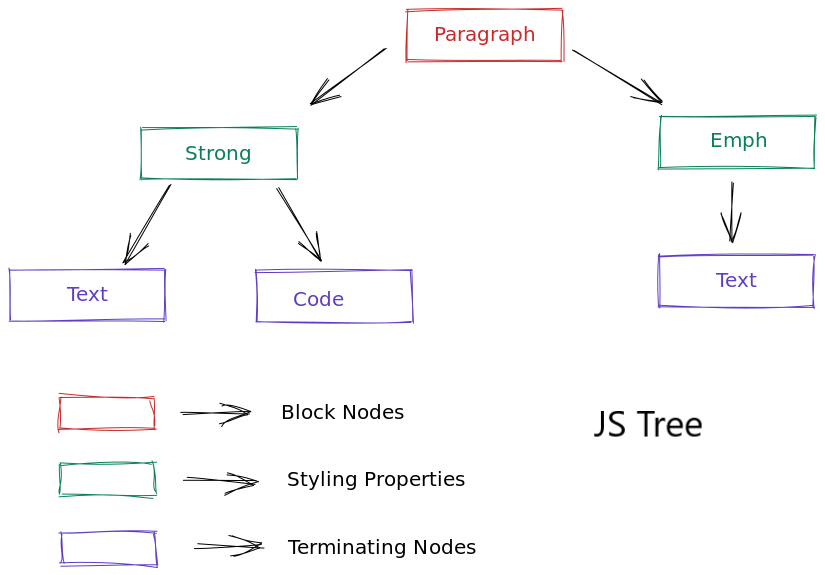
The above JS can be represented in a tree form as:
Things were going smooth and the transformer was being improved with each PR until… a challenge came.
Challenge-1: Transformation Logic Failure
The transformation logic which was used currently could not handle the nesting of elements. This means it was unable to parse the below text:
Hello world.
As you can see above, strong is nested inside italics.
Solution: Rewriting the transformation logic by using the depth first search(DFS) for converting CiceroMark<->JSON.
Reason: From the image of the JS tree above, it is visible that each node that is responsible for rendering the text will always be present as the leaf node. To generate an OOXML for the current leaf node, keep track of the styling properties it has visited and use it to generate OOXML for the same.
The image below shows the tree structure for the CiceroMark and OOXML. 
Explanation of the DFS for CiceroMark<->JSON
- If the node belongs to
blocknodes(paragraph, clause, heading), use DFS for the current node. - If the node belongs to
propertiesnodes(emphasis, link, strong, etc.) append them to properties - If the node belongs to
terminatingnodes(text, inline-code, softbreak, thematic break, etc.) then use the properties to generate the OOXML.
Demo of the process flow

Rewriting of the CiceroMark->OOXML and OOXML->CiceroMark.
After the rewriting it was time to resume the transformation of different entities on which I worked upon and it went fine before I stumbled on another challenge:
Challenge-2: Optional and Conditional Nodes
The optional and conditional nodes, unlike others, can have different nodes depending on conditions.  The main problem that arose here was to hide the
The main problem that arose here was to hide the nodes of false conditions. Solution: The problem was resolved by using the w:vanish property of OOXML. It specifies that the content is to be hidden from display at display time. In other words, it is similar to display:none of CSS. More information here.
Finally, I wrote a transformer that can convert the major of the CiceroMark nodes to corresponding OOXML tags.
Side by side, I integrated the current transformation with the markus. This ensures that one can use the transformation using the CLI.
Create and view the transformed file
To create a file, use:
Markus usage
Note: Save files with XML format. See here for the conversions possible.
To use the created XML file, one can follow these steps:
{kind=link}
- Copy the
XMLin the file. - Open MS-WORD. Insert the OOXML using the Script Lab add-in. Be sure to install the add-in.
Alternatively, one can also right-click on the document and open it with MS-WORD to see the transformed content.
In the future, integration with the add-in will ensure interaction with the transformed file with advanced features. Currently, the features are limited via the above two methods.
Result
Markdown Example
Paste the above here and switch to the ast tab to see the corresponding CiceroMark.
Markdown Representation

OOXML Representation

Sample CiceroMark and OOXML

Current Standing
Currently, the CiceroMark<->OOXML can do the following conversions:
- Text
- Emphasis
- Heading
- Variable
- Softbreak
- Strong
- Code
- Thematic Break
- Codeblock
- Clause
- Link
- Optional
- Conditional
- Formula
The project was started as an improvement to the already existing transformer and a total of 29 PR were made including various commit messages and 8 issues that were made.
Future Goals
The future seems bright for the transformer. There are still few nodes left that require transformation. Some of them are:
- List
- Blockquote
- Image
In addition, the transformer needs to be integrated properly with the add-in so that the working can be made more smooth and easier for users.
Experience
GSoC was a fun journey for me. I got to learn many things this summer by working on the project. From a person, who didn’t know much about MS Word (didn’t use it much) to understanding the syntax on which word documents are built upon was enthralling. I would like to thank my mentors Aman and Dan for helping me out whenever I got stuck with or was not clear of the approach for solving a particular problem. I would also like to thank the Accord Project Community for providing me the opportunity to work with them and helping me understand the ecosystem and its workings.
I am hoping to contribute to Accord Project in the future by improving the services they offer either by coding or by providing ideas for the same. I will also help others who are looking to contribute to Accord Project by explaining things and the ecosystem passing the torch to the successors. Ultimately, GSoC is just the beginning.